The Meaning of Density
Contents
15.2. The Meaning of Density#
When we work with a discrete random variable \(X\), a natural component of our calculations is the chance that \(X\) has a particular value \(k\). That’s the probability we denote by \(P(X = k)\).
What is the analog of \(P(X = k)\) when \(X\) has a density? If your answer is \(P(X = x)\) for any number \(x\), prepare to be disconcerted by the next paragraph.
15.2.1. If \(X\) Has a Density, Each Individual Value Has Probability 0#
If \(X\) has a density, then probabilities are defined as areas under the density curve. The area of a line is zero. So if \(X\) has a density, then for every \(x\),
“But \(X\) has to be some value!” is a natural reaction to this. Take a moment now to reflect on the wonders of adding uncountably many zeros. On the real line, each point has length zero but intervals have positive length. On the plane, each line has area zero but rectangles have positive area. Calculus is powerful.
The fact that the chance of any single value is 0 actually reduces some bookkeeping. When we are calculating probabilities involving random variables that have densities, we don’t have to worry about whether we should or should not include endpoints of intervals. The chance of each endpoint is 0, so for example,
Being able to drop the equal sign like this is a major departure from calculations involving discrete random variables; \(P(X = k)\) has disappeared. But it does have an analog if we think in terms of infinitesimals.
15.2.2. An Infinitesimal Calculation#
In the theory of Riemann integration, the area under a curve is calculated by discrete approximation. The interval on the horizontal axis is divided into tiny little segments. Each segment becomes the base of a very narrow rectangle with a height determined by the curve. The total area of all these rectangular slivers is an approximation to the integral. As you make the slivers narrower, the sum approaches the area under the curve.
Let’s examine this in the case of the density we used as our example in the previous section:
Here is one of those narrow slivers.
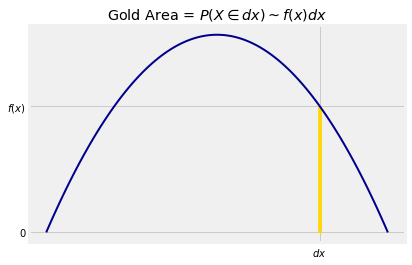
We will now set up some notation that will be used repeatedly in the course.
\(x\) is a point on the horizontal axis
\(dx\) stands for two things (this considerably simplifies writing):
a tiny interval around \(x\)
the length of the tiny interval
Now \(\{X \in dx \}\) is notation for “\(X\) is in a tiny interval of length \(dx\) around the point \(x\)”. Don’t worry about exactly what “around” means. It won’t matter as we’ll be taking limits as \(dx\) goes to 0.
In this notation, the area of the gold sliver is essentially that of a rectangle with height \(f(x)\) and width \(dx\). We write
where as usual \(\sim\) means that the ratio of the two sides goes to 1 as \(dx\) goes to 0.
We have seen that \(f(x)\) is not a probability. But for a tiny \(dx\), the product \(f(x)dx\) is essentially the probability that “\(X\) is just around \(x\)”.
This gives us an important analogy. When \(X\) is discrete, then
When \(X\) has density \(f\), then
The calculus notation is clever as well as powerful. It involves two analogies:
\(f(x)dx\) is the chance the chance that \(X\) is just around \(x\)
the integral is a continuous version of the sum
Quick Check
A random variable \(X\) has density \(f\) that is positive on the entire real number line. True or false:
(a) For all \(x\), \(P(X=x) = f(x)\).
(b) For all \(x\), \(0 \le f(x) \le 1\).
(c) For all \(x\), \(P(X = x) = 0\).
(d) For all \(x\), \(P(X \in dx) \sim f(x)dx\).
Answer
False, False, True, True
Quick Check
A random variable \(X\) has density \(f\). Arrange the following from largest to smallest. If two entries are the same, put an \(=\) sign between them; it doesn’t matter in which order you write them.
\(P(a \le X < b)\), \(P(a < X < b)\), \(P(a \le X \le b)\)
Answer
All three are equal
15.2.3. Probability Density#
We can rewrite \(P(X \in dx) \sim f(x)dx\) as
The function \(f\) represents probability per unit length. That is why \(f\) is called a probability density function.
Let’s take another look at the graph of \(f\).
If you simulate multiple independent copies of a random variable that has this density (exactly how to do that will be the subject of the next lab), then for example the simulated values will be more crowded around 0.5 than around 0.2.
The function simulate_f takes the number of copies as its argument and displays a histogram of the simulated values overlaid with the graph of \(f\).
simulate_f(10000)
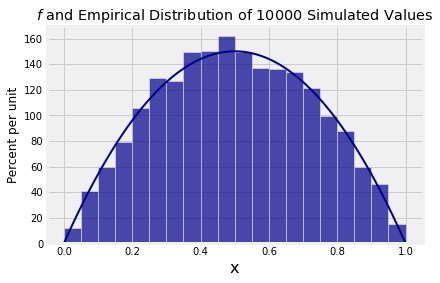
The distribution of 10,000 simulated values follows \(f\) pretty closely.
Compare the vertical scale of the histogram above with the vertical scale of the graph of \(f\) that we drew earlier. You can see that they are the same apart from a conversion of proportions to percents.
Now you have a better understanding of why all histograms in Data 8 are drawn to the density scale, with heights calculated as
so that the units of height are “percent per unit on the horizontal axis”.
Not only does this way of drawing histograms allow you to account for bins of different widths, as discussed in Data 8, it also leads directly to probability densities of random variables. You can think of the density curve as what the empirical histogram of the simulated values would look like if you had infinitely many simulations and infinitely narrow bins.